

一貫性のあるキャラクターを生成するためのFlux.1 LoRAの作成方法

Flux.1はとてもリアルな表現ができると好評です。そして特に指摘すると、手の指がきれいに表現されます。そして、ローマ字のロゴなどもとてもきれいに再現が可能です。Midjourney(有料)級の画実が無料で再現できる。
AIアートの分野は日々進化し、私たちがイメージしているキャラクターやシーンを、よりリアルで美しく生成できるようになっています。中でも注目されているのが、画像生成モデルの「Flux.1」とそのカスタマイズ可能な機能「LoRA(Low-Rank Adaptation)」です。このブログでは、Flux.1を使って一貫性のあるキャラクターを生成するために、LoRAの作成方法についてわかりやすく解説していきます。
なぜFlux.1とLoRAを使うのか?
キャラクターデザインやアニメーション、イラスト制作において、一貫性を持たせることは非常に重要です。Flux.1は、ミッドジャーニーなどの高品質な画像生成モデルに匹敵するレベルの画質を無料で提供しつつ、LoRAを活用することで、独自のスタイルや特定のキャラクターの特徴を学習させることが可能です。これにより、プロフェッショナルなデザインから個人のクリエイティブプロジェクトまで、さまざまな用途に対応できるのが魅力です。
LoRAを使ったキャラクター生成のメリット
LoRAを使用することで、Flux.1モデルに簡単に新しい情報を追加し、特定のキャラクターのデザインやポーズ、表情などの一貫性を保ちながら出力できます。以下のようなメリットがあります。
- 高画質のキャラクター生成: Flux.1は、Midjourneyレベルの画質を提供し、細部までこだわったリアルで鮮明なキャラクターを出力します。
- 無料で使える: ミッドジャーニーや他の画像生成サービスとは異なり、Flux.1は基本的に無料で利用できるため、コストを気にせずに使えるのが大きな利点です。
- カスタマイズ可能な出力: LoRAを活用することで、自分だけのオリジナルキャラクターを作り出し、さまざまなシーンやスタイルに合わせたカスタマイズが可能です。
- 柔軟なトレーニング: LoRAの学習プロセスは非常に柔軟で、短時間で新しいスタイルを追加したり、特定のテーマに沿ったキャラクターを生成したりできます。
次章の内容
次章では、実際にFlux.1のLoRAを作成し、一貫性のあるキャラクターを生成するステップを具体的に説明していきます。設定方法や必要なツール、LoRAのトレーニング方法についても触れていきますので、これからAIアートに挑戦したい方はぜひお見逃しなく!
今回は、アイドル犬の”うた銀”をAI学習させて、最終的に動画生成してミュージックビデオを作ります。
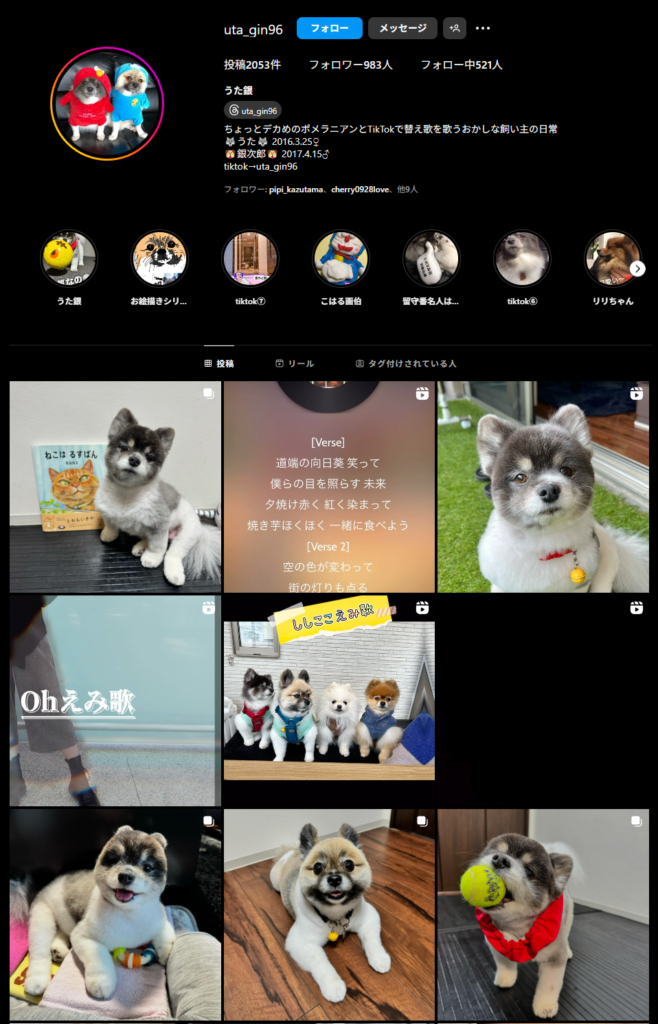
ステップ1:まずは画像の準備
愛犬家の、うた銀さん(飼い主)かた105枚の生写真を提供受けました。
- うたちゃん(白黒)ポメラニアンの犬
- 銀ちゃん(白、茶、黒のミックス)ポメラニアンの犬
この2匹をAI学習させます。
余計な背景を削除する。
犬以外の背景を削除し、AIに犬だけを認識して学習してもらいます。
画像を切り抜いて、背景を透明化し、.png画像として書き出します。


使用する透過ツールはこちら
いろんなツールがありますが、こちらは1024pxまでの画像が無料です。また、学習には1024pxレベルでちょうどよいため、おすすめです。
https://clipdrop.co/remove-background
背景を切り取り、犬だけになった

これで画像の準備は完了です。おおむね20枚以上の多種多様な画像(寝ている、走っている、食べている、服を着ているなど)を準備します。この作業時間は3時間ほどかかりました。1枚一枚削除するので、手間がかかります。バッチ処理できるサイトがあれば有料でもありかも。
いろんなシチュエーションの画像があったほうが、バラエティー飛んだ結果が生まれやすい
ステップ2:画像のキャプションをつける
先ほど用意した背景カット画像(.png)と、同名のテキストファイル(.txt)が並んでいます。今からこれを作成します。

Stable Diffusion WEB UI でTAGGERエクステンションを導入する
Stable Diffusion WEB UIがある前提でお話しします。
Extensions>Install from URL>URL for extension’s git repositoryに以下を入力してinstallボタンを押します。
http://github.com/picobyte/stable-diffusion-webui-wd14-tagger.git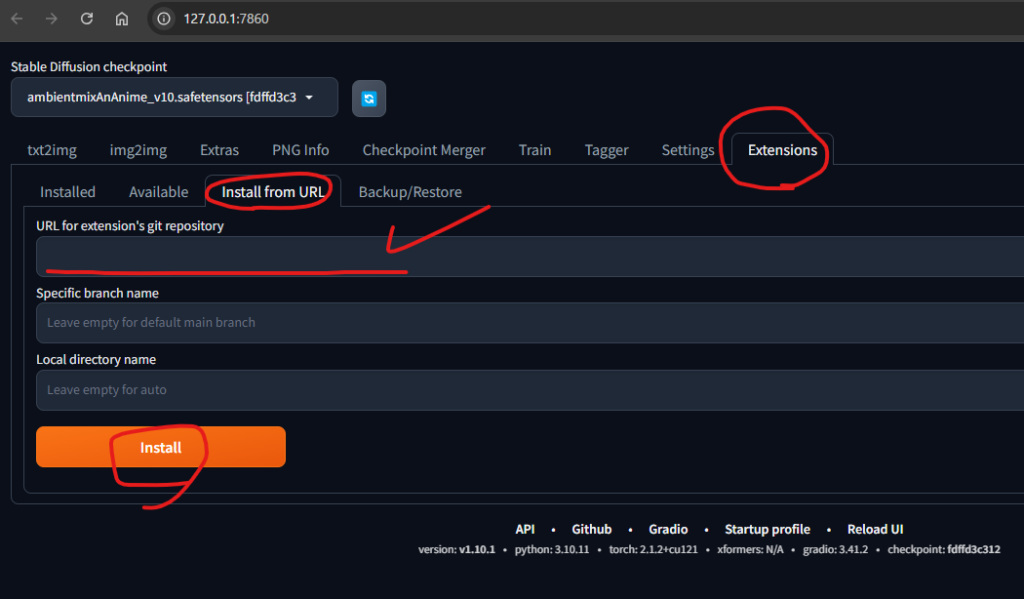
その後、再起動するか、Apply and restart UIを押します。
すると、stable-diffusion-webui-wd14-taggerがインストールされます。
stable-diffusion-webui-wd14-taggerの使い方
インストールしたら、上部のタブにTaggerタブが表示されていると思います。
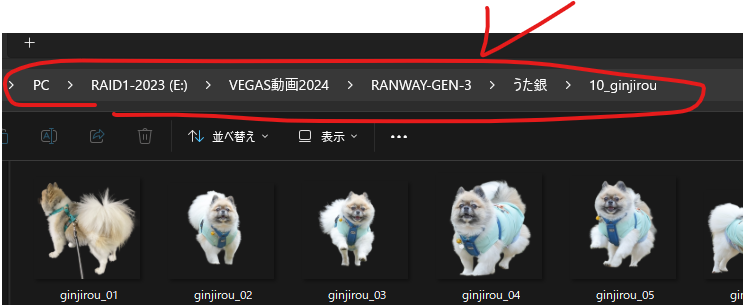
画像の入っているフォルダを図のようにWINDOWSのエキスプローラーからコピーして入力
以下は例です。
E:\VEGAS動画2024\RANWAY-GEN-3\うた銀\10_ginjirou
Batch from directryタブをクリック(これにより、フォルダ内のすべての画像に対して一括処理ができます。)
コピーして、入力します。私の場合OUTPUTも同じフォルダにしました。
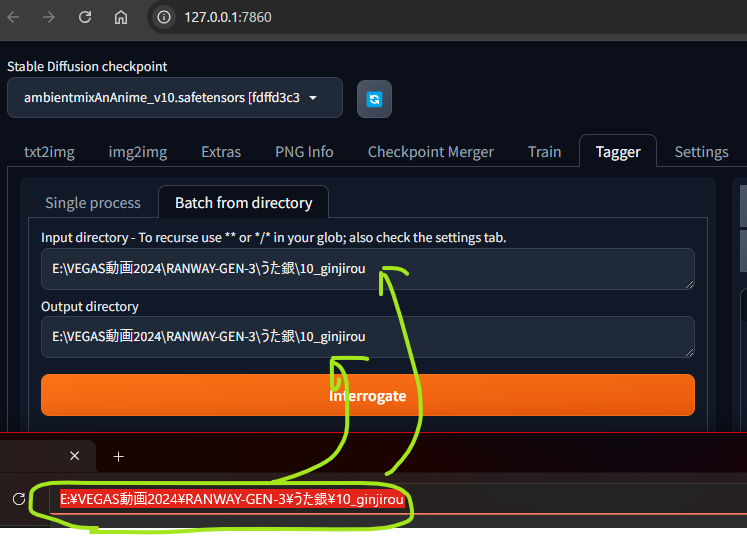
その後、”INTERRROGATE”を押します。(オレンジのボタン)
数秒で、以下のようにグラフが表示され、画像から読み取れる情報をテキストにして書き出してくれます。
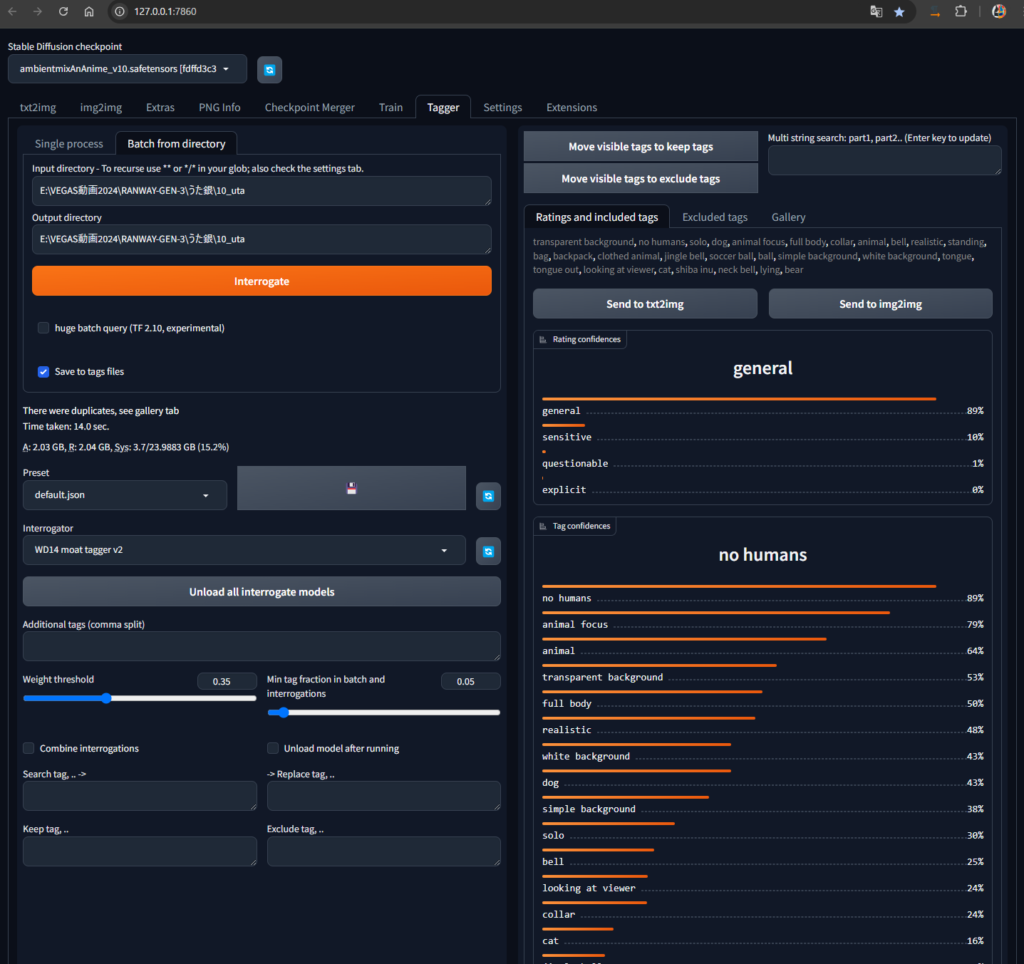
フォルダ内はこんな感じ。一括してできるのはとても便利です。手動でテキストファイルを作るには、メモ帳などを使用します。(面倒くさいです。)
テキスト情報の中身は、次のようになっていました。おおむね似たようなタグです。
きちんとdog(犬)と認識されていますね。
ポメラニアンと犬種までは書かれていませんが、場合によっては書き足しても良いかもしれません。
no humans, animal focus, transparent background, animal, full body, dog, collar, closed eyes最後に、フォルダをZIP圧縮します。画像とテキストが入ったフォルダをWINDOWSの圧縮でZIPにします。
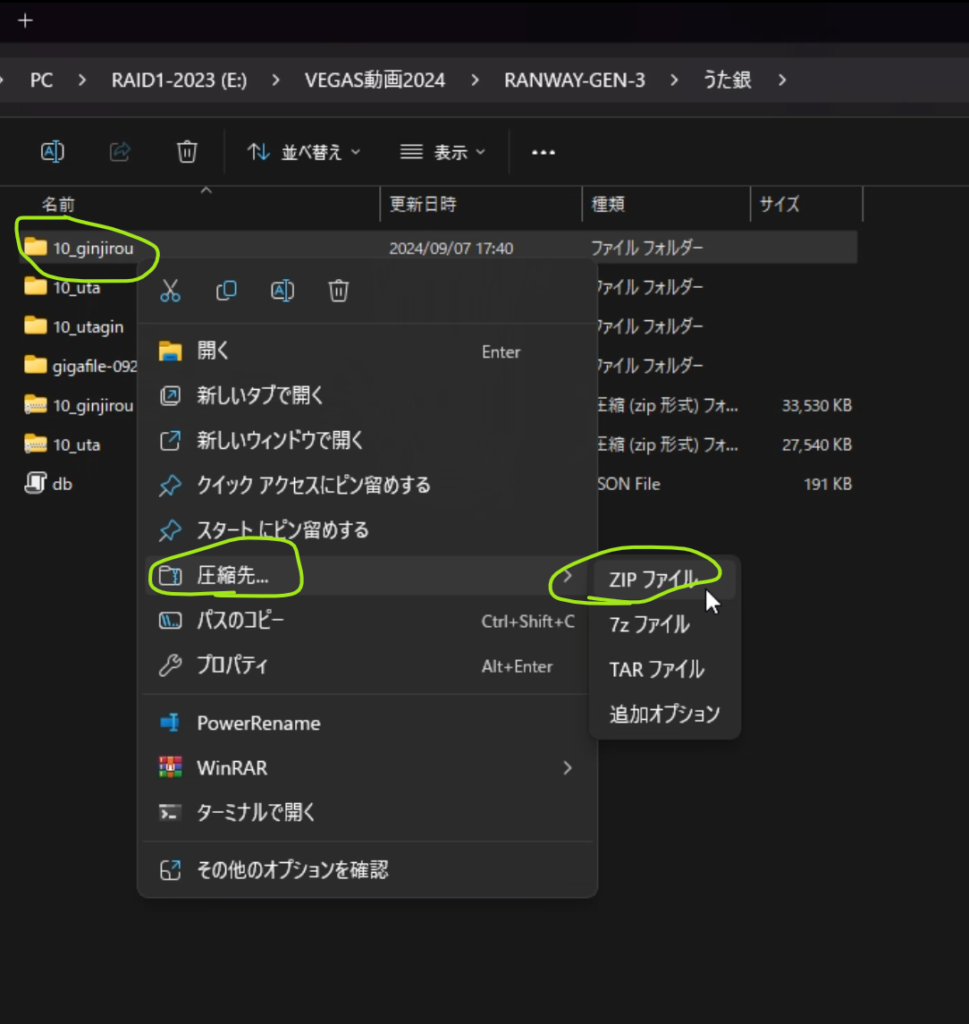
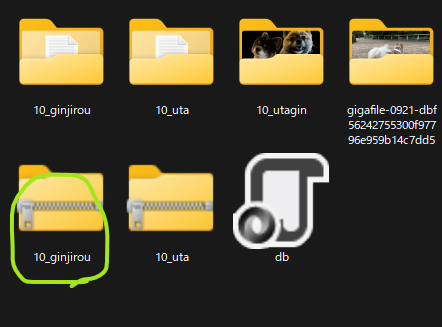
このように圧縮ファイルができました。
ステップ3:Flux.1用のLoRAを作成する
Flux.1用のLoRAを作成する手段は現時点であまり多くはありません。
また、最低グラフィックボードのメモリが24GB必要になります。そういった場合はクライド処理が一般的になります。
KohyaSS-GUIで、通常のSDXL向けLoRAを作成してみましたが、なんか似ていない。
でも、それっぽい。という使い方には向いてるかも。ちなみに無料です。




この失敗から、Flux.1用のLoRAを作成することにしました。高性能なことに期待をこめて。
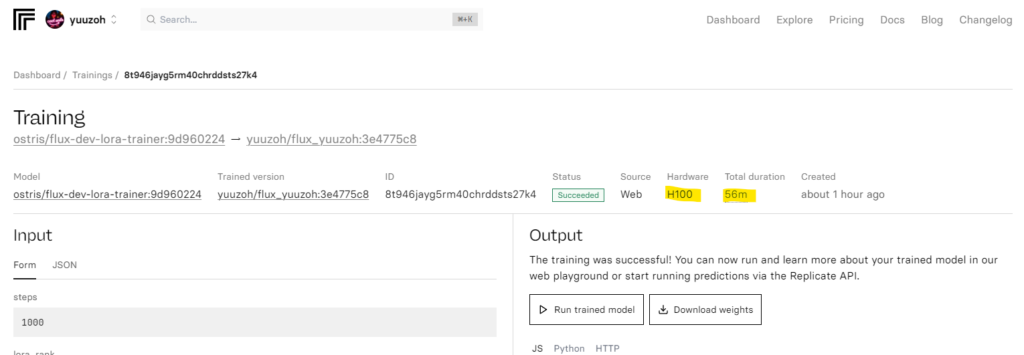
ostris/flux-dev-lora-trainerの使い方
サイトはこちら↓
ステップ0 決済情報の入力
ostris/flux-dev-lora-trainerを使用するにはクレジットカードの課金設定が必要です。
これをしていないと、入力を進めてもエラーになります。最初はこの課金手段がわからず困りました。
アカウントをクリック
アカウントセッティング
Billingをクリック
画面上はカード入力画面ではないが、クレジットカード入力後にこの画面になります。
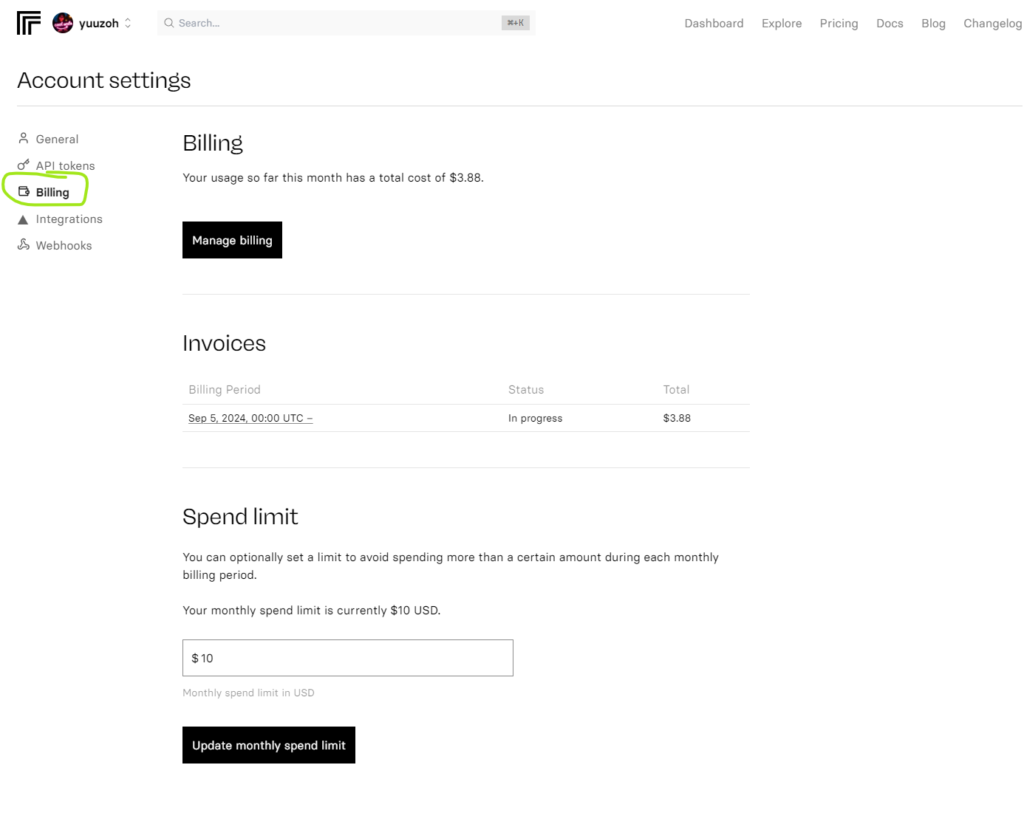
すでに2回使用して、請求額が出ているが、3.88USD=おおむね562円だ(1USD=145円計算)
カードが準備できたら元のページへ戻る。ostris/flux-dev-lora-trainer
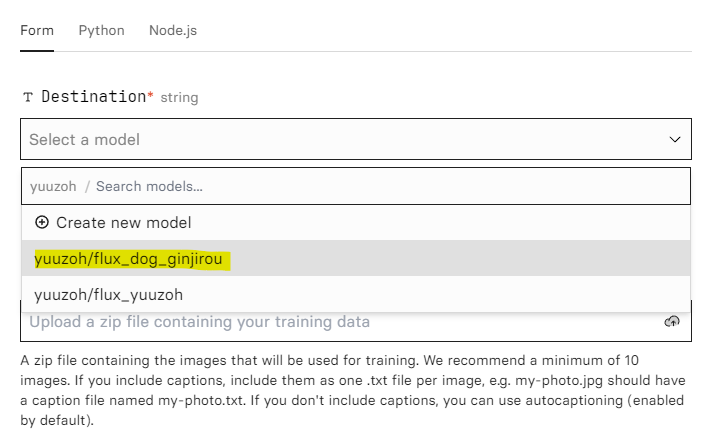
ステップ1 名前を付ける
まずは、Destinationで「Create NEW model」を押して、適当な名前を付けます。入力します。
そして入力してできた「yuuzoh/flux_dog_ginjirou model.」を選択します。
例は以下の通り
ステップ2 画像をアップロードする
先ほど作ったZIPファイルをアップロードします。
ステップ3 トリガーワード入力する
トリガーワードはステップ1と同じにしました。「flux_dog_ginjirou」
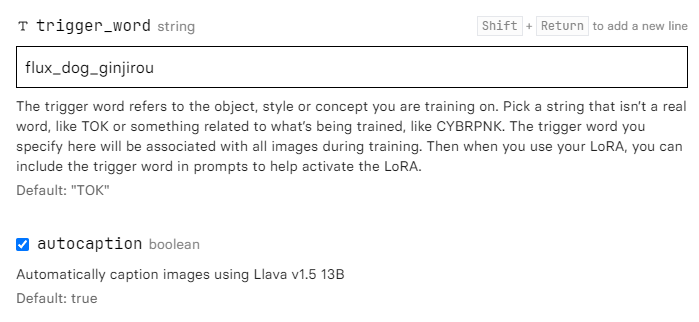
ステップ4 トレーニング開始
その他の設定はあまりいじらなくてよさげ。デフォルトのまま出力してみましょう。
resolutionは入力した画像の最大幅です。1024が基本ですが、このままでよいと思います。
Create Trainingをクリックで始まります。
始まった感が無いけど。
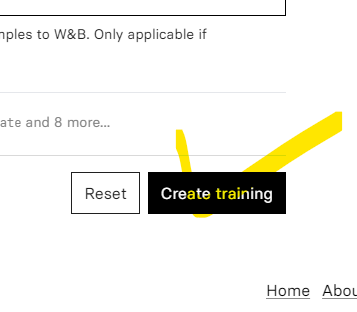
約30分ほどで、出来上がっていました。さすがクラウドのGPU!早いです。
「Download weights」からダウンロードする。
ダウンロードすると圧縮ファイルで書き出せます。
これで、LoRAを作成できました。
ステップ4:LoRAを解凍する
stable-diffusion-webuiなどで実際に使用してみる。
trained_model.tarという圧縮ファイルができているのでWINDOWSで(すべてを展開)解凍します。
ファイル内に”lora.safetensors”というファイルがありますね。これを任意の名前に変更します。
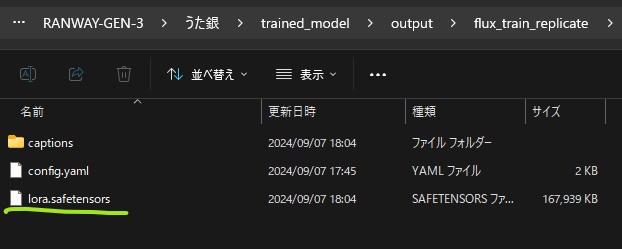
lora.safetensors > flux_dog_ginjirou.safetensors にしました。
このファイルをstable-diffusion-webuiなど(ご使用の)のLoRAフォルダに入れてください。
だいたい以下のような場所に格納されています。
今回はSwarmUIを使用しました。
ステップ5:SwarmUIで画像生成
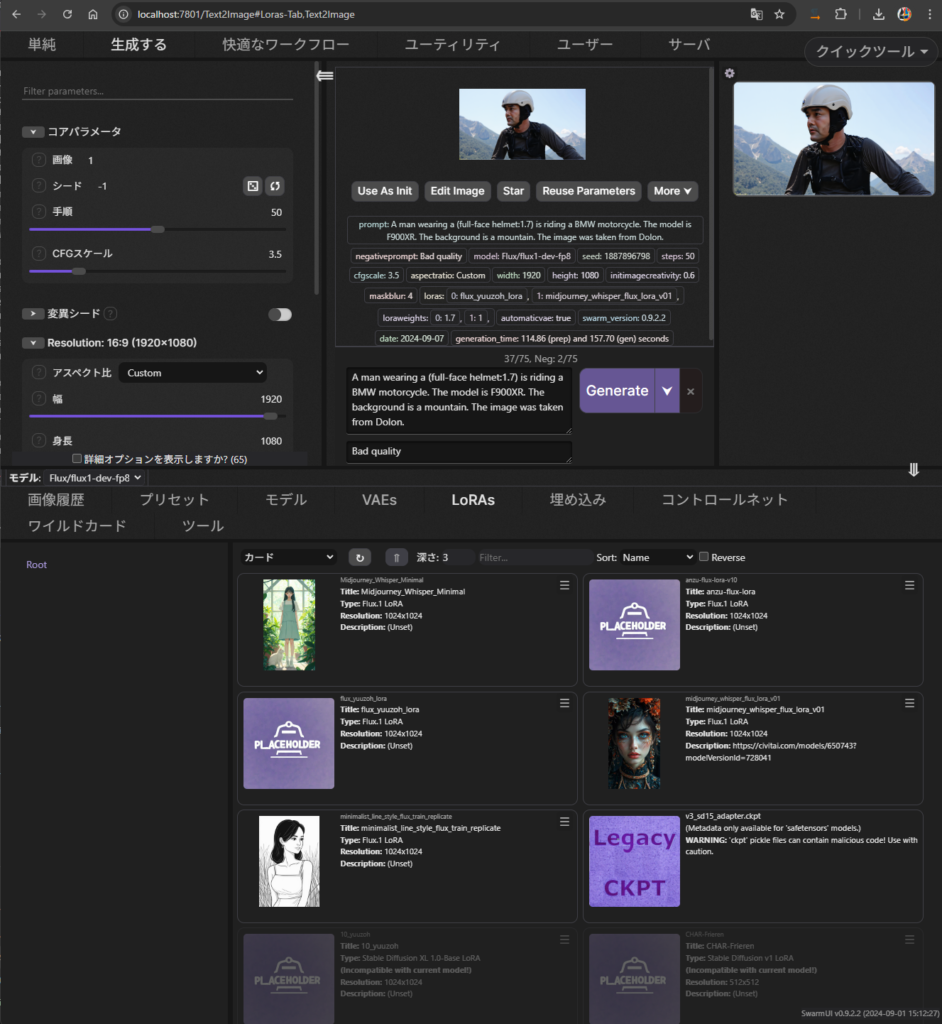
LoRAを読み込む
SwarmUIを起動したら、LoRAタブの更新ボタンをクリック
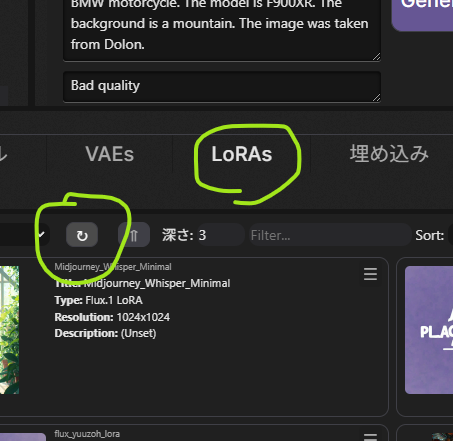
すると先ほど作った flux_dog_ginjirou が出てきます。
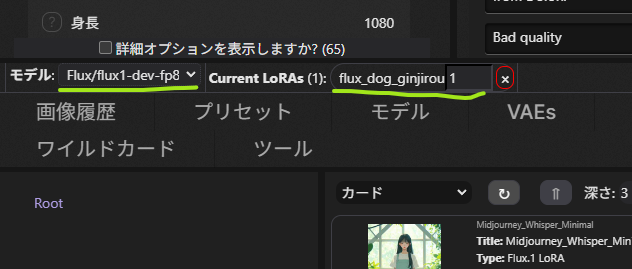
- 使用するモデルはflux1-dev-fp8
- ローラはflux_dog_ginjirouを選択します。
設定値
flux1-dev-fp8のモデルを使用するときは、
- Stepを50
- CFGスケールを3.5(今回はこの数値を2ぐらいにした方が良い結果を生みました。)
にしました。設定値は随時調整してください。
プロンプト入力
今回はシンプルにこのプロンプトを英語で入力しました。
Pomeranian runs through the grass(ポメラニアンは草むらを走る)
設定値は以下のとおりです。生成時間はRTX4090で4分ほどです。
prompt: Pomeranian runs through the grass,negativeprompt: Bad quality,model: Flux/flux1-dev-fp8,images: 4,seed: 758756214,steps: 50,cfgscale: 3.5,aspectratio: Custom,width: 1920,height: 1080,initimagecreativity: 0.6,maskblur: 4,loras: 0: flux_dog_ginjirou,,loraweights: 0: 1,,automaticvae: true,swarm_version: 0.9.2.2,date: 2024-09-07,generation_time: 0.00 (prep) and 148.63 (gen) seconds,
AI銀ちゃんの爆誕です!
かわいいですね。ここまで出来たら、次に銀ちゃんの面白おかしいストーリーを考えます。
ChatGPT4o で銀ちゃんのストーリーを(作成)整えます。

CFGスケールをかなり低くしてあげると、良好になりました。flux1-dev-fp8だとCFGスケールを高くする必要性が無いのかもしれません。それほどに優秀ということかも。
パラメーターを少し変更してみる
- ステップ数:50
- CFGスケール:1
- LoRA:0.8

ディティールがぐっと上がりました!飼い主さんの評判も非常に良いです!

次のブログで、動画化していきます。お楽しみに!

コメント